Architecture queue mode avec workers dedies
4 patterns d’agents modulaires
Gestion mémoire et controle des couts
Scoring de confiance et validation humaine
9 pieges terrain constates en mission
Cas concret : +1h/jour gagnee chez un client PME
Déployer un agent IA dans n8n en local prend 15 minutes. Le maintenir en production sans incident pendant 6 mois demande une architecture, des patterns et des garde-fous que la plupart des tutoriels ne couvrent pas. Ce guide condense les retours terrain de missions Ocade Fusion aupres de PME et ETI qui ont franchi ce cap en 2026. Architecture, mémoire, sécurité, monitoring : chaque section repond à une question concrete que les équipes se posent avant de passer en production.
Votre agent est-il production-ready ?
0/24Besoin d'aide pour mettre ça en place dans votre entreprise ?
Discutons de votre projet →Architecture production : queue mode, workers et Docker Compose
En mode par defaut, n8n exécuté tout dans un seul processus Node.js. Un workflow agent qui appelle un LLM pendant 30 secondes bloque les autres exécutions. En production, le queue mode separe les roles : l’instance principale gere les webhooks et l’interface, les workers executent les workflows en parallele. Redis sert de file d’attente entre les deux.
PostgreSQL est obligatoire - SQLite ne supporte pas les acces concurrents du queue mode (documentation n8n). Un Docker Compose type comprend 4 services : Traefik (reverse proxy HTTPS), n8n-main, n8n-worker et PostgreSQL. Le parametre N8N_WORKER_CONCURRENCY definit combien de workflows un worker traite simultanement - commencer a 2 ou 4, puis ajuster selon que les workflows sont I/O-bound (augmenter) ou CPU-bound (reduire). Pour scaler, une seule commande : docker compose up -d --scale n8n-worker=3. Point critique : toutes les instances doivent partager la même ENCRYPTION_KEY, sinon les workers ne pourront pas dechiffrer les credentials.
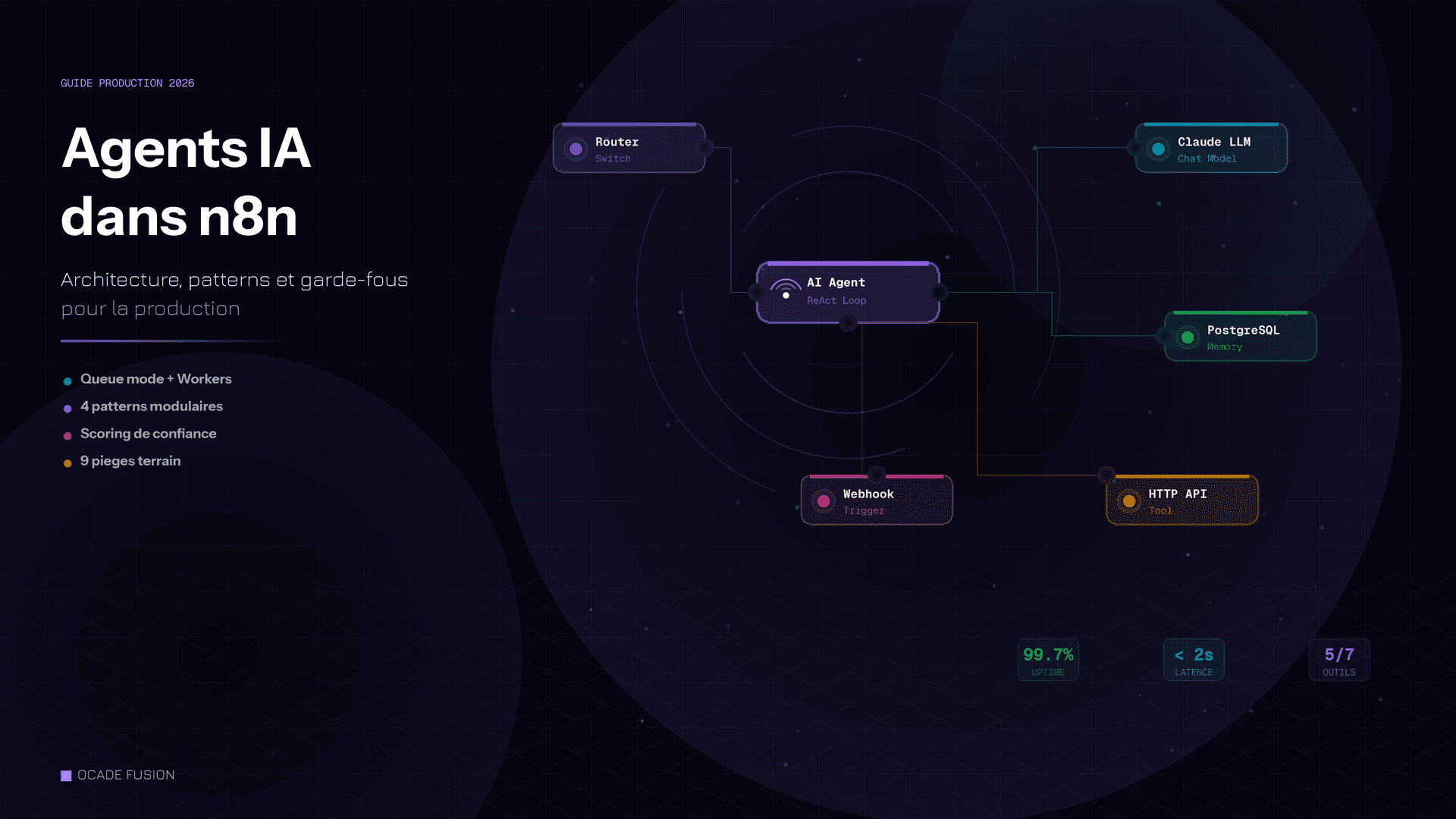
Le nœud AI Agent en 2026 : ce qui a change
Le nœud AI Agent de n8n repose sur le pattern ReAct (Reasoning + Acting) : le modele analyse la requête, choisit un outil, recoit le résultat, raisonne a nouveau et compose la réponse finale. Ce cycle se repete jusqu’a resolution ou limite d’iterations. En 2026, le nœud supporte nativement Claude, GPT-4, Gemini, Mistral et les modeles locaux via Ollama.
Quatre sous-nœuds se connectent a l’agent : le Chat Model (choix du LLM), la mémoire (contexte conversationnel), les outils (API externes, bases de données, sous-workflows) et la sortie structuree (format de réponse). Chaque outil nécessite un nom, une description ecrite pour le LLM et un schema d’entree. La qualité des descriptions d’outils determine directement la fiabilite de sélection par l’agent - une description vague provoque des appels errones. En formation Ocade Fusion, c’est le premier point qu’on corrige : la plupart des echecs agents viennent de descriptions d’outils mal redigees, pas du modele lui-même.
4 patterns d’agents modulaires
Un agent monolithique avec 15 outils fonctionne en demo. En production, la performance se degrade au-dela de 5 a 7 outils par agent (n8n Blog) : chaque requête oblige le LLM a evaluer toutes les options, ce qui augmente la latence et le cout en tokens.
Quatre patterns resolvent ce problème :
- Agent mono-tache : un seul agent, 3-5 outils, un perimetre clair. Ideal pour commencer.
- Routeur + agents specialises : un Switch node analyse la requête et l’envoie vers le sous-workflow adapte (commandes, SAV, facturation). Chaque sous-agent a ses propres outils.
- Pipeline sequentiel : l’output d’un agent alimente le suivant. Exemple : extraction → enrichissement → redaction.
- Orchestrateur multi-agents : un agent principal utilise le nœud AI Agent Tool pour appeler d’autres agents comme outils. Ajouter ou retirer un sous-agent ne casse pas le workflow principal.
En prestation Ocade Fusion, le pattern routeur couvre 80 % des cas metier. Le multi-agents n’est justifie que pour les flux complexes avec plus de 3 domaines metier distincts.
Mémoire et contexte : Postgres, Redis, Window Buffer
Sans mémoire, l’agent oublie tout entre deux messages. n8n propose trois options, chacune adaptee à un contexte different.
La Simple Memory (buffer en mémoire) stocke l’historique dans la session du workflow. Rapide, zero configuration, mais les données disparaissent au redemarrage. Convient pour les agents sans suivi de conversation. La mémoire PostgreSQL persiste l’historique en base SQL. Les conversations survivent aux redemarrages, déploiements et montees en charge. C’est le choix recommande pour la production (Towards AI). La mémoire Redis est plus rapide en lecture/ecriture mais volatile par defaut - a utiliser comme cache de session avec une persistence configuree.
En pratique, le Window Buffer Memory limite le nombre de messages envoyes au LLM (par exemple les 10 derniers echanges). Cela controle les couts : un historique de 50 messages sur Claude Opus consomme plusieurs milliers de tokens à chaque appel. Fixer la fenetre a 10-15 messages est un bon compromis cout/contexte pour la majorite des cas metier.
MCP : transformer n8n en hub d’orchestration IA
Le Model Context Protocol (MCP) connecte les agents IA a des sources de données externes via un standard ouvert. n8n supporte MCP dans les deux directions : consommer des serveurs MCP comme outils pour ses agents, et exposer ses propres workflows comme serveurs MCP pour des clients externes (documentation n8n).
En pratique, un workflow qui demarre par un nœud MCP Server Trigger devient un outil que Claude Desktop, VS Code ou Cursor peuvent appeler directement. Inversement, un agent n8n peut consommer un serveur MCP existant (base de données, documentation interne, ticketing) sans code d’intégration custom. Le serveur MCP gere la logique outil, n8n gere l’orchestration, le LLM gere le raisonnement. Cette architecture permet de reutiliser les mêmes connecteurs MCP entre n8n, Claude Code et d’autres clients, sans dupliquer le code d’intégration. Pour un article detaille sur le déploiement MCP, voir notre guide Déployer un serveur MCP dans n8n.
Sécurité et credentials en production
En production, les credentials stockees dans la base n8n representent un risque : une compromission de l’instance expose toutes les clés API. La fonctionnalite External Secrets (edition Enterprise) permet de deleguer le stockage à un coffre-fort externe - HashiCorp Vault, AWS Secrets Manager, Azure Key Vault, GCP Secrets Manager ou 1Password (documentation n8n).
Le principe : n8n ne stocke jamais les credentials réelles. Il interroge le coffre-fort au moment de l’exécution, utilise la clé, puis la laisse expirer. Avec Vault, il est possible de générer des credentials PostgreSQL a duree de vie limitee pour chaque exécution. Pour les équipes sans edition Enterprise, le nœud communautaire n8n-nodes-hashi-vault offre une intégration directe. Depuis n8n 2.0, les Task Runners isoles empechent egalement les Code nodes d’acceder au système de fichiers du serveur, ce qui bloque l’exfiltration de secrets via du code malveillant injecte dans un workflow.
Human-in-the-loop et scoring de confiance
Un agent autonome qui envoie un email errone à un client coute plus cher que l’absence d’automatisation. Le human-in-the-loop ajoute un point de validation humaine avant les actions critiques. n8n 2.0 corrige un problème majeur : les sous-workflows avec nœuds Wait (approbation Slack, validation email) retournent desormais correctement les données au workflow parent.
Le pattern recommande : implementer un scoring de confiance dans l’agent. Le LLM evalue sa propre certitude sur une echelle 0-100. Au-dessus de 80, l’action s’exécuté automatiquement. Entre 50 et 80, l’agent envoie une demande de validation via Slack ou email avec un resume de ce qu’il compte faire. En dessous de 50, le ticket est escalade à un humain sans action automatique. Ce seuil se calibre par domaine : un agent de classification de factures peut tolerer 70 en seuil auto, un agent qui modifie des données clients devrait rester a 90. Pour approfondir, voir notre article Human-in-the-Loop dans n8n.
Monitoring, erreurs et alertes
Chaque workflow de production doit avoir un Error Workflow associe - sans exception. Le nœud Error Trigger se déclenché uniquement sur les exécutions automatiques, pas les tests manuels (documentation n8n). Il capture l’ID d’exécution, le nom du workflow et le message d’erreur.
Trois couches de monitoring complementaires :
- Niveau nœud : configurer les retries automatiques (1-3 tentatives avec delai exponentiel) sur les nœuds d’appel API et LLM pour absorber les erreurs transitoires.
- Niveau workflow : un Error Workflow centralise qui envoie les alertes Slack/email avec l’exécution ID pour un acces direct aux logs.
- Niveau instance : metriques Prometheus exposees par n8n, visualisees dans Grafana - taux d’erreur, temps d’exécution, profondeur de queue.
Eviter la fatigue d’alerte : filtrer par severite et regrouper par fenetre temporelle (pas plus d’une notification par workflow par tranche de 5 minutes). Stocker les erreurs dans une Data Table en plus des alertes temps réel - les alertes se perdent, le journal reste.
n8n 2.0 : ce que ca change pour les agents
La version 2.0 de n8n, sortie debut 2026, apporte trois changements structurants pour les deployments agents (annonce officielle).
Publish/Save separe le brouillon de la version live. Modifier un agent en cours d’exécution ne casse plus la production - le bouton Save preserve les modifications sans affecter la version publiee. Le bouton Publish pousse explicitement les changements en production quand on est pret. Ce mecanisme supprime la cause numero un d’incidents en production : la modification accidentelle d’un workflow actif.
Task Runners isoles executent les Code nodes dans un environnement sandbox par defaut. Une boucle infinie ou une fuite mémoire dans un script ne fait plus tomber l’instance entiere. Pour les agents qui utilisent des Code nodes pour du preprocessing, c’est un filet de sécurité critique.
SQLite pooling accelere les performances jusqu’a 10x selon les benchmarks n8n, avec une reduction significative des erreurs “Database Locked”. Un outil de migration scanne l’instance et fournit un rapport des changements nécessaires avant mise à jour.
9 pieges terrain : retour d’experience Ocade Fusion
Apres plusieurs missions de déploiement d’agents n8n en entreprise (formations, prestations, accompagnement PME), voici les erreurs les plus frequentes constatees sur le terrain :
- Temperature et prompt system negliges : en formation, c’est l’erreur la plus frequente. Un prompt system ambigu produit des résultats imprevisibles. Et la temperature par defaut (souvent 0.7) généré de la creativite la ou il faut de la précision. Pour du parsing de données ou de la classification, descendre a 0.1-0.3. Un cas réel : un LLM mal parametre a produit des erreurs de parsing sur des données entrantes, avec un traitement partiel de la demande parce que le prompt system laissait trop de marge d’interpretation.
- Mauvais choix de modele : tous les LLM ne se valent pas sur chaque tache. Utiliser Claude Opus pour classifier des emails est du gaspillage. Utiliser Haiku pour du raisonnement complexe produit des erreurs. Mapper chaque tache au modele adapte : Haiku/GPT-4o-mini pour le tri et la classification, Sonnet pour le traitement standard, Opus uniquement pour le raisonnement avance.
- Descriptions d’outils vagues : “Envoie un email” au lieu de “Envoie un email professionnel au client dont l’adresse est fournie dans le champ to, avec le sujet et le corps specifies”. Le LLM ne devine pas les conventions metier.
- Pas de limite d’iterations : un agent sans plafond peut boucler indefiniment et consommer des centaines de dollars en tokens en une nuit. Fixer un maximum de 5 a 10 iterations.
- Mémoire illimitee : envoyer l’historique complet au LLM à chaque appel. A 100 messages, le cout explose et le modele perd le fil. Utiliser un Window Buffer de 10-15 messages.
- Tester en manuel uniquement : l’Error Trigger ne se déclenché qu’en exécution automatique. Les bugs de production ne sont detectes qu’au premier incident réel.
- Un seul agent pour tout : au-dela de 7 outils, la fiabilite chute. Decouper en agents specialises.
- Ignorer les couts : un agent Claude Opus avec historique complet sur un workflow haute frequence (100 exécutions/jour) peut depasser 500 euros par mois. Mesurer le cout par exécution et choisir le modele adapte à chaque tache. Exemple concret : un client PME (PH Taxi) a gagne plus d’une heure par jour grâce à un workflow d’ajout automatique de courses dans son agenda - mais le ROI n’a ete positif qu’apres avoir remplace le modele initial surdimensionne par un modele plus leger et adapte à la tache.
Checklist : votre agent n8n est-il production-ready ?
Avant de passer un agent en production, vérifier ces points :
- Architecture : queue mode active, PostgreSQL configure, encryption key partagee entre instances
- Agent : maximum 7 outils par agent, descriptions d’outils detaillees, limite d’iterations fixee
- Mémoire : stockage persistant (Postgres ou Redis), Window Buffer configure, cout par exécution estime
- Sécurité : credentials dans un coffre-fort externe ou chiffrees, Task Runners actifs (n8n 2.0), pas de secrets dans le JSON du workflow
- Erreurs : Error Workflow associe, alertes Slack/email configurees, retries sur les nœuds API/LLM
- Monitoring : metriques Prometheus/Grafana, journal d’erreurs persistant, alertes avec seuils anti-fatigue
- Validation : scoring de confiance implemente, human-in-the-loop sur les actions critiques, seuils calibres par domaine
- Déploiement : Publish/Save utilise (n8n 2.0), backup des workflows sur Git, plan de rollback documente
Déployer un agent IA en production avec n8n n’est plus un pari technologique en 2026 - c’est un processus d’ingenierie avec des patterns eprouves. La difference entre un prototype qui impressionne et un système qui tourne sans incident se joue sur l’architecture, les garde-fous et le monitoring. Les équipes qui investissent 20 % de temps supplementaire sur ces fondations evitent 80 % des incidents de production.
Mis à jour : avril 2026